Autor

prof. UEK, dr hab. Joanna Wyrobek
Katedra Finansów Przedsiębiorstw. Członek zespołu problemu węzłowego 3.3 Modele wytwarzania i dystrybucji dóbr i usług publicznych.
Czwarta rewolucja przemysłowa a wielkie zbiory danych i wykrywanie na ich podstawie oszustw finansowych
1. Wielkie zbiory danych
Czwartą rewolucję przemysłową zapoczątkowała cyfryzacja. Cyfryzacja to przeniesienie wielu aspektów życia człowieka ze świata realnego do wirtualnego, a także rozwój infrastruktury elektronicznej, która to umożliwia. Wraz z postępem cyfryzacji rozwijają się także metody interakcji człowieka z komputerami i urządzeniami elektronicznymi. Obecnie trudno jest funkcjonować bez podstawowej chociaż znajomości Internetu i obsługi urządzeń elektronicznych.
Przez Internet i za pośrednictwem komputerów oraz telefonów komórkowych realizowane są między innymi: kontakty międzyludzkie (emaile, rozmowy telefoniczne, smsy, mmsy, czaty, fora dyskusyjne), zakupy, operacje finansowe, wiele osób wykonuje część lub całość swojej pracy zawodowej za pomocą komputerów i często Internetu, procesy decyzyjne w przedsiębiorstwach i innych instytucjach też często dokonywane są za pomocą komunikacji zdalnej i spotkań wirtualnych. Internet dotarł zresztą znacznie dalej w głąb życia ludzkiego, ponieważ wiele osób prowadzi swoje osobiste blogi w Internecie, także sporo osób korzysta z internetowych portali randkowych. Do Internetu coraz częściej podłączane są nie tylko komputery, ale także urządzenia domowego AGD, dzięki czemu można m.in. sprawdzić stan lodówki w czasie zakupów (niektóre lodówki potrafią wygenerować listę zakupów dla danego użytkownika), czy sterować i nadzorować pracę pralki czy klimatyzatora (lub ogrzewania centralnego). Komputeryzacja zaszła tak daleko, że współcześnie aby dokonać naprawy samochodu w większości przypadków najpierw należy podłączyć jego komputer pokładowy do komputera mechanika, aby odczytać potencjalne komunikaty o błędach oraz ostrzeżenia (gniazdo diagnostyczne). Nawet telewizory to obecnie małe komputery, które także są podłączone do Internetu, dzięki czemu użytkownicy mogą oglądać filmy z portali internetowych. Prowadzi to do istotnej konkluzji – a mianowicie, że prawie każdy człowiek pozostawia za sobą ogromne ilości danych w Internecie. Nie tylko zresztą człowiek, także przedsiębiorstwa czy jakiekolwiek organizacje czy instytucje.

O każdym człowieku, jak i instytucji w Internecie można dowiedzieć się kiedy się urodził czy też kiedy dana instytucja powstała, o lokalizacji, bardzo często można znaleźć różne opinie na forach dyskusyjnych, w przypadku przedsiębiorstw ich sprawozdania finansowe, wypowiedzi członków zarządu, rekomendacje, preferencje i zachowania w różnych sytuacjach. Nie wszystkie dane są publicznie dostępne, gdyż część danych ma charakter poufny i prywatny, ale i tak nawet na podstawie publicznych danych można się sporo dowiedzieć o człowieku czy przedsiębiorstwie. Instytucje wymiaru sprawiedliwości nota bene mają dostęp także do danych poufnych o ile taki dostęp zostanie im nadany wyrokiem sądu w toczących się śledztwach.
Także wewnątrz przedsiębiorstw czy instytucji gromadzone są w wersji elektronicznej dane, które kiedyś funkcjonowały wyłącznie w postaci papierowej. Każde zadanie otrzymuje swój numer identyfikacyjny i przechodząc przez kolejne osoby wykonujące czynności z nim związane, można śledzić jego przebieg między stanowiskami, a także czas i jego koszty. Wszystkie transakcje jakie są np. realizowane na giełdzie (dokonane transakcje, a także złożone zlecenia) są także rejestrowane i potem archiwizowane. Nawet sposób przeglądania witryny internetowej sklepu jest także rejestrowany, aby sprawdzić jakie strony klient odwiedził, jakie produkty oglądał, czy dodał produkty do koszyka, czy dokonał zakupu. Każdy sklep czy przedsiębiorstwo gromadzą w wersji elektronicznej informacje ile produktów wytworzyli bądź kupili, ile zostało sprzedanych, jakie są potrzebne dostawy na kolejny dzień.
W ten sposób gromadzone są ogromne ilości danych nazywane po angielsku big data, który to termin niekiedy jest tłumaczony na język polski jako duże zbiory danych. Z jednej strony, te dane są niezwykle cenne, gdyż zawierają niekiedy bezcenne informacje pozwalające dokonywać poprawnych decyzji w przyszłości. Z drugiej strony, liczba tych danych jest przeogromna i konieczne jest posługiwanie się odpowiednimi narzędziami do obróbki tak ogromnej ilości danych. Na przykład, popularny program Ms Excel pozwala na używanie arkuszy kalkulacyjnych składających się z miliona wierszy. Ale jeżeli by ktoś spróbował w tym programie wyliczyć chociażby stopy zwrotu dla miliona obserwacji, będzie to bardzo długo trwało – samo wczytanie takiego pliku zabierze sporo czasu. Zazwyczaj duże dane są przetwarzane najpierw w programach bazodanowych, a potem w programach statystycznych lub narzędziach dedykowanych do wielkich danych.
2. Uczenie maszynowe i sztuczna inteligencja jako narzędzia przetwarzania wielkich zbiorów danych
Jednym z narzędzi przetwarzania wielkich zbiorów danych są algorytmy uczenia maszynowego i sztucznej inteligencji. Cechą wspólną tych metod jest poszukiwanie wzorców i zazwyczaj także zapamiętywanie tych wzorców, aby umieć je potem znaleźć w nowej partii danych. Metody te można podzielić na takie, które same poszukują wzorców (bez nadzoru człowieka czy informacji zwrotnej) oraz na metody, które najpierw się uczy, czyli przedstawia im się dane i informuje o wystąpieniu lub niewystąpieniu określonego wzorca.
Metody niewymagające nadzoru to m.in. algorytm k-NN, czyli algorytm wyszukiwania najbliższych sąsiadów. Każda obserwacja – może to być np. sprawozdanie finansowe wybranego przedsiębiorstwa jest zapisywane jako wielowymiarowy wektor, czyli ciąg liczb (opisujących wszystkie po kolei elementy sprawozdania finansowego). Człowiek informuje algorytm ile w populacji występuje odrębnych od siebie grup (np. przedsiębiorstwa upadłe i te w dobrej sytuacji finansowej). Algorytm stosując różne miary odległości pogrupuje wszystkie przedsiębiorstwa na dwie grupy, które według wybranej miary odległości są w obrębie grup do siebie podobne, a pomiędzy grupami do siebie niepodobne. Człowiek potem może ocenić czy taki podział ma sens i jest użyteczny.
Z metod wymagających nadzoru człowieka popularne są drzewa decyzyjne, metoda wektorów nośnych, naiwne wnioskowanie bayesowskie, analiza dyskryminacyjna, sztuczne sieci neuronowe. Wymienione algorytmy są oparte na odmiennym aparacie matematycznym, ale łączy je sposób działania. Najpierw następuje proces uczenia. W ramach uczenia tworzone są pary składające się z wejściowego obiektu uczącego (zwykle wektora) oraz pożądanej odpowiedzi (zwykle liczby). Następnie algorytmy przetwarzają te pary danych i dostosowują swoją wewnętrzną strukturę tak, aby były w stanie na podstawie obiektu uczącego wygenerować pożądaną przez nadzorcę odpowiedź. Potem można takich nauczonych algorytmów użyć do nowych danych z nieznaną odpowiedzią i algorytmy dopiszą do każdego nowego wektora danych jaka wypada dla tego wektora danych odpowiedź. Na przykład, można przedstawić określony zbiór sprawozdań finansowych firm, które dopuściły się przestępstw finansowych (fałszowanie sprawozdań, łapówkarstwo, kradzież patentów, itd.) z informacją, że są to firmy-oszuści, a potem algorytmy dla nowych danych będą identyfikować kolejne przedsiębiorstwa, które prawdopodobnie także dopuściły się oszustw.
Każdy algorytm przy tym stosuje inne metody nauczenia się jak generować poprawną odpowiedź. W przypadku drzew decyzyjnych dla wszystkich dostępnych informacji o obiektach testuje się która zmienna z wejściowego obiektu uczącego (w przypadku sprawozdań finansowych który element sprawozdania finansowego) jest najsilniej powiązana z pożądaną odpowiedzią. Na przykład, w przypadku poszukiwania oszustów może okazać się, że najsilniej to widać po rozliczeniach międzyokresowych, że większość przedsiębiorstw oszustów miało niezwykle wysokie te rozliczenia, podczas gdy uczciwe jednostki miały je dużo niższe. Tworzona jest pierwsza noda drzewa, która dla pewnej wartości tych rozliczeń (albo udziału w aktywach tych rozliczeń) dzieli obserwacje na dwie grupy. Potem poszukuje się kolejnego elementu obiektu uczącego, który także w wyraźny sposób rozróżnia uczciwe i nieuczciwe pomioty. W ten sposób budowane jest drzewo decyzyjne. Budowę drzewa zwykle kończy się wtedy, kiedy już nie ma kolejnych kandydatów na nody, albo drzewo poprawnie rozdzieliło przedsiębiorstwa na uczciwe i nieuczciwe. Drzewo decyzyjne podzieli grupę uczącą na dużo podzbiorów, ale każdy z tych podzbiorów powinien zawierać albo prawie wyłącznie oszustów, albo prawie wyłącznie uczciwe przedsiębiorstwa.
Zamiast jednego drzewa decyzyjnego można zbudować cały las. Robi się to tak, że mając wektory opisujące obserwacje losuje się pewną część obserwacji i pewną część elementów składających się na te wektory. W efekcie dla każdego losowania tworzy się inne drzewo. Każde drzewo uczono w oparciu o mniejszą ilość danych uczących niż cała próba. Każde drzewo potem będzie dokonywało swojej decyzji czy jednostka jest oszustem czy nie, a ostateczna decyzja będzie oparta na głosowaniu większościowym. Metodę tę nazywa się losowym lasem.
Innym wariantem bardziej skomplikowanej struktury opartej na drzewach decyzyjnych jest algorytm wzmacniania gradientowego. W tym przypadku najpierw tworzy się pierwsze drzewo, o ograniczonej ilości nod. Następnie testuje się dla jakich obserwacji drzewo dokonuje błędnej klasyfikacji. Wiedząc już dla których obserwacji drzewo popełnia błędy, tworzone jest kolejne drzewo, które ma poprawnie klasyfikować te obserwacje, z którymi nie poradziło sobie pierwsze drzewo. Następnie na tej samej zasadzie tworzone jest trzecie drzewo i kolejne. Po nauczeniu algorytmu i korzystaniu z niego na nowych danych najpierw odpowiedź generuje pierwsze drzewo (klasyfikację), potem drugie, itd. Pierwsze drzewo „wie” dla których obserwacji musi polegać na odpowiedzi uzyskanej od drugiego drzewa, a drugie drzewo wie kiedy ma polegać na odpowiedzi uzyskanej od trzeciego drzewa.
Oprócz drzew decyzyjnych popularnym algorytmem jest metoda wektorów nośnych, czyli support vector machines (SVM). W tym przypadku obiekty uczące są znowu wektorami danych. Takie wektory danych można sobie wyobrazić jako wektory w wielowymiarowej przestrzeni. Istotą algorytmu SVM jest znalezienie takiej hiperpłaszczyzny, która rozdzieli wielowymiarową przestrzeń na dwie części (albo więcej części, w zależności od problemu). Czyli po jednej stronie hiperpłaszczyzny mają się znaleźć wektory opisujące uczciwe przedsiębiorstwa, a po drugiej stronie płaszczyzny mają się znaleźć wektory opisujące nieuczciwe przedsiębiorstwa. Potem można algorytmowi przedstawić nowe dane, a on sprawdzi po której stronie hiperpłaszczyzny te dane się znajdują i na tej podstawie udzieli odpowiedzi na temat uczciwości danego przedsiębiorstwa.
Naiwne wnioskowanie Bayesowskie opiera się na prawdopodobieństwie warunkowym. Dane zdarzenie z dużym prawdopodobieństwem wystąpi o ile wystąpiło inne zdarzenie. Dla firm – oszustów oblicza się prawdopodobieństwo jakiegoś zdarzenia X1 pod warunkiem, że ten podmiot dopuścił się oszustwa (zdarzenie Y). Potem oblicza się prawdopodobieństwo innego zdarzenia – X2, znowu pod warunkiem, że podmiot dopuścił się oszustwa. Ostatecznie chodzi o obliczenie prawdopodobieństwa koniunkcji wielu zdarzeń: X1 oraz X2 oraz X3… itd. Pod warunkiem, że najpierw przedsiębiorstwo popełniło oszustwo. Reguła Bayesa pozwala potem obliczyć prawdopodobieństwo oszustwa (zdarzenia Y) pod warunkiem wystąpienia zdarzeń X1, X2, .. itd. Naiwność w nazwie algorytmu zaś wynika stąd, że zakłada się, że zdarzenia X1, X2, … są od siebie niezależne (co zwykle nie jest do końca prawdą). Na przykład, można obliczyć prawdopodobieństwo wysokich rozliczeń międzyokresowych połączonych z ujemnym kapitałem obrotowym netto oraz ujemną średnią wartością operacyjnych przepływów pieniężnych dla populacji przedsiębiorstw, które popełniły oszustwo. Potem, za pomocą reguły Bayesa i założenia niezależności można wyliczać prawdopodobieństwo oszustwa pod warunkiem wystąpienia tych zdarzeń w określonym stopniu. Uzyskane prawdopodobieństwo określa jakie są szanse, że analizowane przedsiębiorstwo jest oszustem.
Analiza dyskryminacyjna także wymaga pewnej liczby obserwacji dla których znana jest odpowiedź (przedsiębiorstw sklasyfikowanych jako oszuści albo nie oszuści). Istotne jest to, że ta metoda wymaga, aby posługiwać się wartościami wystandaryzowanymi, czyli każdy element z wektora uczącego powinien przyjmować wartości z tego samego zakresu wartości – na przykład od minus jeden do plus jeden. Zwykle w przypadku danych finansowych uzyskuje się to poprzez dzielenie wartości ze sprawozdania finansowego przez jakiś inny element ze sprawozdania finansowego (czyli używa się nie bezpośrednio danych ze sprawozdania finansowego, tylko tzw. wskaźników finansowych). Algorytm działa w ten sposób, że dla każdego elementu z wektora uczącego dla wszystkich obserwacji z danej klasy (w analizowanym przypadku firm-oszustów i firm uczciwych) obliczana jest wartość średnia (metoda zakłada, że wszystkie te elementy mają rozkład normalny) – osobno dla firm oszustów i osobno dla firm uczciwych. Potem dla każdego elementu wektora opisującego daną obserwację liczy się odległość tego elementu od każdej średniej. W końcu sumuje się te odległości podniesione do kwadratu i ocenia czy taka odległość jest najmniejsza od klasy firm uczciwych czy nieuczciwych (do której klasy ma dana obserwacja najbliżej).
W końcu sztuczne sieci neuronowe mają jeszcze inny mechanizm działania. Neuron to pojedyncze równanie, w którym można zmieniać współczynniki stojące przy zmiennych. Zmienne to dane z wektora uczącego (a potem z wektora dla którego chcemy uzyskać odpowiedź). Współczynniki na początku są całkowicie losowe. Neurony ustawia się w warstwach. Liczbę neuronów ustala się dość subiektywnie, chociaż są różne porady ile tych neuronów należy użyć w zależności od tego ile elementów znajduje się w wektorze uczącym (czyli ile zmiennych liczbowych opisuje dane przedsiębiorstwo). Pierwsza warstwa neuronów dostaje dane z wektora uczącego, przemnaża je przez losowo dobrane wagi i następnie uzyskaną wartość zwykle jeszcze przekształca w ten sposób, żeby niskie wartości stały się bliskie zeru, a wysokie bliskie jedynce (czyli na przykład poddaje się uzyskaną wartość jako argument funkcji sigmoid, która właśnie tak działa). Tak uzyskane wartości ze wszystkich neuronów warstwy wejściowej są przesyłane do drugiej warstwy neuronów. To może być już ostatnia warstwa, ale może być znacznie więcej tych warstw. Kolejna warstwa robi to samo – pobiera od wszystkich neuronów z warstwy wejściowej ich wyniki (bliskie zeru lub jedynce), przemnaża przez losowo wybrane wagi, oblicza wynik, przekształca znowu w wartość bliską zeru lub jedynce i wysyła dalej. Jeżeli druga warstwa była już ostatnią, to neuronów w ostatniej warstwie jest tyle, do ilu klas sieć ma klasyfikować obserwacje (przedsiębiorstwa). W przypadku wykrywania oszustw są dwie klasy (kategorie) – oszust albo uczciwy. Na etapie uczenia się uzyskany wektor końcowy nie jest zgodny z pożądaną odpowiedzią. W pożądanym wektorze w zależności od obserwacji (przedsiębiorstwa) powinien być albo wektor [1,0] albo [0,1]. A tymczasem na etapie uczenia się może być jakikolwiek wektor, na przykład [0.5, 0.5] co oznacza, że są równe szanse czy taka firma jest uczciwa czy też nie. Ale to nie koniec procesu uczenia. Teraz następuje propagacja wsteczna. Uzyskany wynik, np. [0.5, 0.5] porównuje się z pożądaną odpowiedzią, niech to będzie [1,0] (co może oznaczać uczciwą firmę). Oblicza się różnicę [0.5, -0.5] i wykorzystuje się ten błąd do korekty wag w neuronach, które po korekcie już nie są losowe. Potem się przepuszcza kolejną obserwację i wynik może być np. taki [0.25, 0.8]. A powinno być [0,1] (oszust). Znowu oblicza się różnicę, którą się wykorzystuje do korekty wag w neuronach. Proces ten powtarza się ogromną liczbę razy, ucząc sieć wielokrotnie na tym samym zbiorze danych, aż w końcu sieć zaczyna dokonywać poprawnej klasyfikacji (udzielać poprawnych odpowiedzi). Wtedy już można przestać uczyć sieć, a zacząć jej używać do klasyfikacji innych przedsiębiorstw, co do których nie wiemy czy są uczciwe czy też nie.
3. Kierunki rozwoju metod identyfikowania nieuczciwych przedsiębiorstw
Znając już podstawowe metody przetwarzania wielkich zbiorów danych w celu identyfikacji nieuczciwych przedsiębiorstw, warto opisać kierunki w jakich badania takie się rozwijają. Tabela 1 pokazuje jakie dane są wykorzystywane do wykrywania nieuczciwych przedsiębiorców.
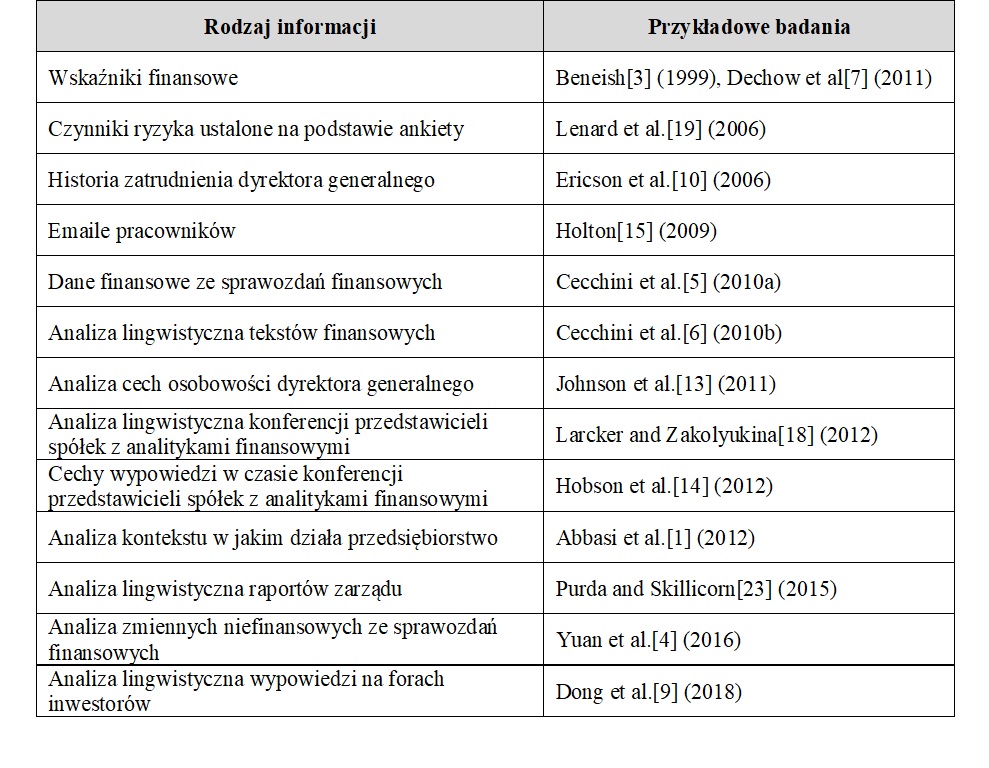
Jak to wynika z Tabeli 1, bardzo wiele elementów pozwala zidentyfikować nieuczciwe przedsiębiorstwa (w większości przypadków cytowane badania skupiały się na fałszowaniu sprawozdań finansowych, ale większość przestępstw finansowych tak czy inaczej skutkowało sprawozdaniem finansowym, które wymagało korekty). Jak widać, badania rozpoczęto od wskaźników finansowych, ale szybko zaczęto je uzupełniać cechami charakteru i historią zatrudnienia dyrektora generalnego, danymi niefinansowymi, stylem i zawartością emaili pracowników oraz raportów zarządu, w końcu opiniami inwestorów o przedsiębiorstwie.
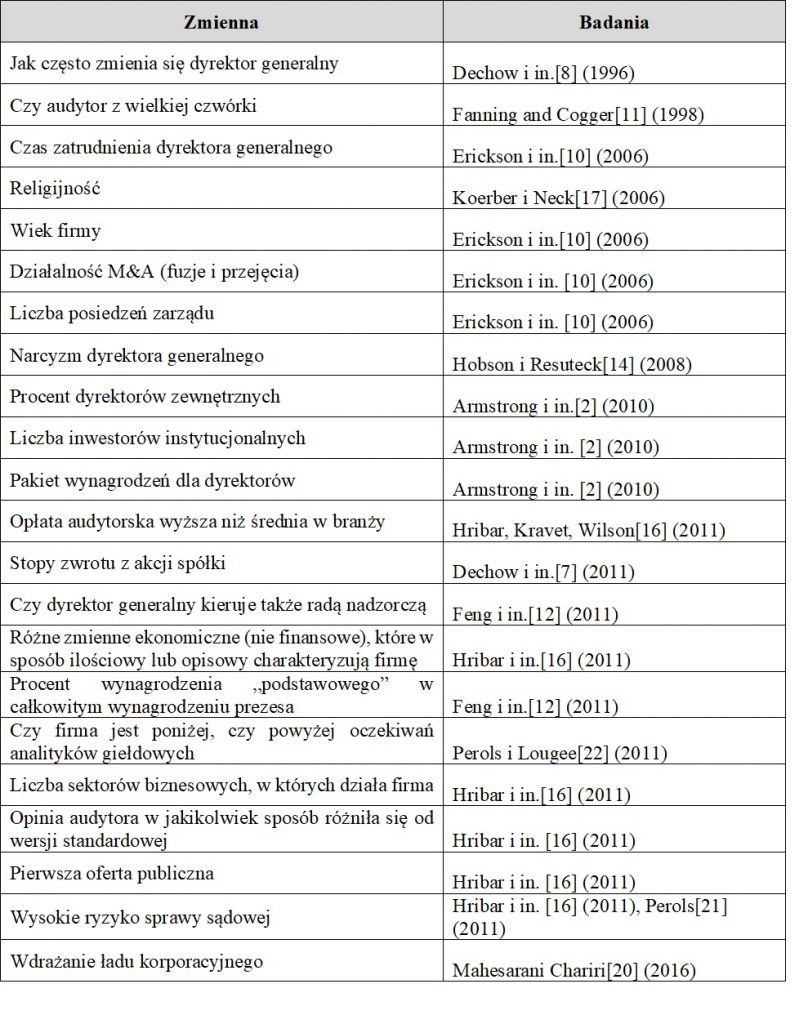
W Tabeli 2 pokazano wybrane konkretne zmienne, które okazały się użyteczne w wykrywaniu fałszowania sprawozdań finansowych. Jak widać, w identyfikowaniu oszustów pomaga wielkość i renoma audytora (oszuści unikają znanych firm audytorskich, bo istnieje większe ryzyko wykrycia nieprawidłowości), czas przez który dany dyrektor generalny kierował przedsiębiorstwem (w celu uniknięcia odpowiedzialności nierzetelni dyrektorzy uciekają pod zmyślonymi powodami), religijność danej wspólnoty z której pochodzą pracownicy, dużo fuzji i przejęć (nieuczciwe podmioty często maskują swoje oszustwa przekształceniami korporacyjnymi), mała liczba spotkań zarządu w roku, odsetek dyrektorów zewnętrznych (osoby niepowiązane z przedsiębiorstwem nadzorują dyrektorów powiązanych z przedsiębiorstwem), niska liczba inwestorów instytucjonalnych (którzy sprawują dodatkową kontrolę nad działaniami zarządu), wyniki spółki poniżej publikowanych prognoz przez zewnętrznych analityków (spółki starają się oszukiwać, aby osiągnąć wyniki jakich spodziewa się od nich rynek), duży udział premii dla dyrektorów za wyniki, a także ryzyko i częstość spraw sądowych (nieuczciwi prezesi stają przed sądem częściej niż uczciwi), brak wdrożonego ładu korporacyjnego, a także narcyzm dyrektora generalnego.
Omawiając publikacje z zakresu wykrywania oszustw trzeba też wspomnieć o prawie Benforda, które podchodzi do wykrywania oszustw inaczej niż opisane wcześniej metody. Poszukuje się wśród zbiorów danych innego rozkładu liczb składających się na sprawozdania finansowe niż przewiduje prawo Benforda.
Jeżeli zaś chodzi o przyszłość badań nad wykorzystaniem danych typu big data do wykrywania oszustw finansowych, to wydaje się, że rośnie zainteresowanie czynnikami psychologicznymi, w tym cechami charakteru dyrektora generalnego a także kultury organizacyjnej w danej jednostce. Rozwijane są obecnie narzędzia identyfikacji cech charakteru na podstawie mowy, zachowania i tekstów (np. Big Five model) dzięki którym można ustalać pewne cechy charakteru dyrektorów generalnych bez przeprowadzania na nich testów psychologicznych. Oprócz tego badania w coraz większym stopniu wykorzystują zawartość Internetu, aby analizować teksty i informacje o przedsiębiorstwie i dyrektorach.
Oczywiście, rozwijają się także narzędzia przetwarzania wielkich zbiorów danych, opisane w tekście algorytmy to metody podstawowe, już obecnie istnieje wiele ich (znacznie bardziej zaawansowanych) wariantów, a codziennie powstają także nowe algorytmy.
Na koniec wartość wspomnieć, że przedstawione narzędzia nie dają stuprocentowej pewności który podmiot jest uczciwy, a który nie, ale potrafią przetwarzać na bieżąco ogromne ilości informacji i wysyłać sygnały ostrzegawcze, jeżeli dany podmiot wydaje się podejrzany. Dalsze działania i kontrole muszą już wykonać ludzie.